
Let's make something clear, I am not a database expert. Though I work with different databases in the past, I would most likely use an ORM but I would never see myself doing SQL queries, until recently.
So I have been doing alot of SQL queries lately for my Postgres DB on Supabase. If you have read my previous blogpost, you know that I use Supabase as the backend for Cafeist. Supabase's Javascript API client is really helpful. It makes it easy to make queries to the API. However, once I started to become more ambitious with the features that I implemented, I realised there were limitations with the existing Javascript client. With that said, I decided to go raw.
Hi there! This post is pretty long, I know. I never been good in writing essays but I wanted to write about this because I consider it to be one of the highlights in my profession as a software engineer. After this callout, I will be talking about how I developed the geolocation feature of Cafeist. Here are some quicklinks for you to jump around if you wanna skip.
Search started to become more complex
One of the key features of Cafeist is it's search engine. Initially, using the Javascript client was enough to query results on the homepage.
Things started to get complicated when I wanted the search results to be filtered with 8 different categories. This is achievable just with the Javascript client.
// ..other code
const supabase = createServerComponentClient<Database>({ cookies })
const sanitisedQuery = decodeURIComponent(props?.query || "")
const sanitisedSort = decodeURIComponent(props?.sort || "")
const sanitisedLocale = decodeURIComponent(props?.filters?.locales || "")
const sanitisedCategories = decodeURIComponent(props?.filters?.categories || "")
const sanitisedAtmospheres = decodeURIComponent(
props?.filters?.atmospheres || ""
)
const sanitisedAccessibilities = decodeURIComponent(
props?.filters?.accessibilities || ""
)
const sanitisedAmenities = decodeURIComponent(props?.filters?.amenities || "")
const sanitisedOfferings = decodeURIComponent(props?.filters?.offerings || "")
const sanitisedServiceOptions = decodeURIComponent(
props?.filters?.serviceOptions || ""
)
const sanitisedPaymentMethods = decodeURIComponent(
props?.filters?.paymentMethods || ""
)
const sort: { key: string; ascending: boolean } = sanitisedSort
? {
key: sanitisedSort.split("-")[0],
ascending: sanitisedSort.split("-")[1].split(":")[1] === "true"
}
: {
key: "created_at",
ascending: false
}
const supabaseQuery = supabase
.from("cafes")
.select(props?.select, { count: "exact", head: false })
.order(sort.key, { ascending: sort.ascending })
.range(0, PAGE_COUNT - 1)
if (props?.query) {
supabaseQuery.textSearch("fts", sanitisedQuery, {
type: "websearch",
config: "english"
})
}
if (sanitisedLocale) {
supabaseQuery.ilike("cafe_addresses.locale", `%${sanitisedLocale}%`)
}
if (sanitisedCategories) {
supabaseQuery.ilike(
"cafe_categories.category_name",
`%${sanitisedCategories}%`
)
}
if (sanitisedAtmospheres) {
supabaseQuery.ilike(
"cafe_atmospheres.atmosphere_name",
`%${sanitisedAtmospheres}%`
)
}
if (sanitisedAccessibilities) {
supabaseQuery.ilike(
"cafe_accessibilities.accessibility_name",
`%${sanitisedAccessibilities}%`
)
}
if (sanitisedAmenities) {
supabaseQuery.ilike("cafe_amenities.amenity_name", `%${sanitisedAmenities}%`)
}
if (sanitisedOfferings) {
supabaseQuery.ilike("cafe_offerings.offering_name", `%${sanitisedOfferings}%`)
}
if (sanitisedServiceOptions) {
supabaseQuery.ilike(
"cafe_service_options.option_name",
`%${sanitisedServiceOptions}%`
)
}
if (sanitisedPaymentMethods) {
supabaseQuery.ilike(
"cafe_payment_methods.payment_method",
`%${sanitisedPaymentMethods}%`
)
}
const { data: cafes, count, error } = await supabaseQuery
if (error) {
console.error(error)
throw JSON.stringify(error)
}
// return code..It got the job done eventhough there are 148 lines of code. This would the beginning of my endless suffering for the next couple of days, so bear with me.
Inception of the location feature
On 16th of August 2023, I stayed up until 7am implementing geolocation to Cafeist.
I got geolocation to work with the results since each of the cafe data that are
in the database have lat and lng columns but here's where it gets really interesting.
I am inspired by how Airbnb does it -- each stay has a distance badge that shows
how far you are with that place. At first I did it by using an NPM library called geolib
and calculate the distance between the user's location and the cafe's location based on
latitude and longitude.
import getDistance from "geolib/es/getDistance"
const distance =
lat && lng
? getDistance(
{ latitude: userLocation.lat, longitude: userLocation.lng },
{ latitude: lat, longitude: lng }
)
: 0This returns the distance in meters. I achieved what's needed, but at the cost of running this function per each item within the results. There are 15 items per result, not including the next set of 15 items when user scrolls lower on the home page. Moreover, it's clientside, so seeing a placeholder load on each item isn't really that nice to see.
I wanted this to be rendered on the server. When the results load in, the distance will also be viewable, but how?
Using cookies to store geolocation
Before I can even think about how I should make it render on the server, I should first think about how can I send the geolocation data to the server? The answer was by using cookies.
Checkout NextJS' documentation about their cookies API. I will be referring to this alot.
Placing the latitude and longitude as cookies was the perfect way to send it to the server so I created some Server Actions since they are functions that will run on the server even if it's called on a client component.
"use server"
import { cookies } from "next/headers"
export async function getLocationCookie() {
const cookieStore = cookies()
return {
lat: Number(cookieStore.get("user-lat")?.value),
lng: Number(cookieStore.get("user-lng")?.value)
}
}
export async function refreshLocationCookie(
lat: number | null,
lng: number | null
) {
const cookieStore = cookies()
// If no location, return
if (!lat || !lng) return { status: 0 }
// Get location from cookies
const existingLat = cookieStore.get("user-lat")?.value
const existingLng = cookieStore.get("user-lng")?.value
if (!existingLat || !existingLng) {
// If no location in cookies, set location
setLocationCookie(lat, lng)
return { status: 1 }
}
// If location is different from existing location, set new location
if (Number(existingLat) !== lat && Number(existingLng) !== lng) {
cookieStore.set("user-lat", lat.toString())
cookieStore.set("user-lng", lng.toString())
}
return { status: 2 }
}
export async function setLocationCookie(
lat: number | null,
lng: number | null
) {
const cookieStore = cookies()
if (!lat && !lng) return
// Set the cookie
cookieStore.set("user-lat", lat!.toString())
cookieStore.set("user-lng", lng!.toString())
return
}Learn more about Server Actions.
These server actions are utilised in a custom hook and is invoked when the user is on the home page. This makes it possible to
- Set the geolocation of the browser to cookies when there is none set.
- Update the geolocation when there is a difference between the existing geolocation data and the new geolocation data.
But what about getting the geolocation data, should I call getLocationCookie() when I need it?
Yes but don't. Doing so will disable ISR and switch the whole route to
render dynamically.
This is because cookies() is considered a dynamic function
cookies() is a Dynamic Function whose returned values cannot be known ahead
of time. Using it in a layout or page will opt a route into dynamic rendering
at request time.
Using middleware to send geolocation data
I wanted to find a way on how I can get cookies and send it to any server components, without touching any server components 🤣.
Then I remembered, NextJS has quite a powerful middleware API. It can get cookies from incoming request headers. To send it over to the server component, I place the data onto the search params to the next URL.
import { createMiddlewareClient } from "@supabase/auth-helpers-nextjs"
import { NextResponse } from "next/server"
import type { NextRequest } from "next/server"
import type { Database } from "@/lib/database.types"
export async function middleware(req: NextRequest) {
const userLat = req.cookies.get("user-lat")?.value
const userLng = req.cookies.get("user-lng")?.value
const res = NextResponse.next()
const supabase = createMiddlewareClient<Database>({ req, res })
await supabase.auth.getSession()
if (!userLat || !userLng) return res
if (req.nextUrl.pathname === "/") {
req.nextUrl.searchParams.set("lt", userLat)
req.nextUrl.searchParams.set("lg", userLng)
}
return NextResponse.rewrite(req.nextUrl.toString())
}All I need to do now is get the geolocation data from the search params, and then I can finally render the distance locally!
Performance concerns
It was a terrible idea to have the distance calculated on the server. Although my home page is static, the time it takes to build that page is longer than expected.
So I started to look at this from a different perspective.
What if, instead of calculating the the distance on the server or the client, I do it on the database?
I started looking around and installed a Postgres extension called PostGIS that allows storing, indexing and querying geographic data. Perfect.
Supabase has a good documentation about how to integrate PostGIS to Postgres
But there is no way for me to call it with the Javascript client. So I decided to write a SQL function that will later replace my existing search query built with the Javascript client.
So I had to do 2 things
- Create a 1:1 copy of my clientside search query , in SQL.
- Add PostGIS to the query.
I started asking ChatGPT a bunch of questions. Question after question I started building the function from the scratch. Honestly at the time, I had no idea what I was writing. SELECT this WHERE that goes here, then SORT BY this and that. It was all gibberish in my head.
I started learning about the different types of JOINS, how to declare variables, return query types, creating VIEWS and more. It felt like I was in a foreign country. I didn't understand a single syntax.
After some time, I managed to come up with a pretty decent function query.
CREATE OR REPLACE FUNCTION search_cafes (
search_input text DEFAULT NULL,
lat float DEFAULT NULL,
long float DEFAULT NULL,
-- filters & sort parameters..
limit_value numeric DEFAULT 15,
offset_value numeric DEFAULT 0
) RETURNS TABLE (
result_count integer,
id uuid,
name text,
rating numeric,
address text,
base64 text,
url text,
location text,
dist_meters float
) AS $$
DECLARE
result_count integer;
BEGIN
SELECT COUNT(*) INTO result_count
FROM cafes
LEFT JOIN LATERAL (
SELECT images_cafes.base64, images_cafes.url
FROM images_cafes
WHERE cafes.id = images_cafes.cafe_id AND (images_cafes.url IS NOT NULL OR images_cafes.base64 IS NOT NULL)
LIMIT 1
) AS filtered_images ON true
LEFT JOIN (
SELECT cafe_id, array_agg(locale) AS locale_names
FROM cafe_addresses
GROUP BY cafe_id
) AS cafe_addresses ON cafes.id = cafe_addresses.cafe_id
-- ...the rest of the joins...
WHERE
(search_input IS NULL OR cafes.fts @@ plainto_tsquery('english', search_input))
AND (filter_locales IS NULL OR cafe_addresses.locale_names && filter_locales)
AND (filter_amenities IS NULL OR cafe_amenities.amenity_names && filter_amenities)
-- ...the rest of the filters...
RETURN QUERY
SELECT result_count, cafes.id, cafes.name, cafes.rating, cafes.address, filtered_images.base64, filtered_images.url, ST_AsText(cafes.location) AS location, ST_Distance(cafes.location, ST_Point(search_cafes.long, search_cafes.lat)::geography) AS dist_meters
FROM cafes
LEFT JOIN LATERAL (
SELECT images_cafes.base64, images_cafes.url
FROM images_cafes
WHERE cafes.id = images_cafes.cafe_id AND (images_cafes.url IS NOT NULL OR images_cafes.base64 IS NOT NULL)
LIMIT 1
) AS filtered_images ON true
LEFT JOIN (
SELECT cafe_id, array_agg(locale) AS locale_names
FROM cafe_addresses
GROUP BY cafe_id
) AS cafe_addresses ON cafes.id = cafe_addresses.cafe_id
-- ...the rest of the joins...
WHERE
(search_input IS NULL OR cafes.fts @@ plainto_tsquery('english', search_input))
AND (filter_locales IS NULL OR cafe_addresses.locale_names && filter_locales)
AND (filter_amenities IS NULL OR cafe_amenities.amenity_names && filter_amenities)
-- ...the rest of the filters...
ORDER BY
CASE
WHEN sort_order = 'desc' AND sort_by_name THEN cafes.name END DESC,
CASE
WHEN sort_order = 'asc' AND sort_by_name THEN cafes.name END ASC,
-- the rest of the sorts--...
CASE
WHEN NOT (sort_by_name OR sort_by_created_at OR sort_by_nearby OR sort_by_rating) THEN cafes.location <-> ST_Point(search_cafes.long, search_cafes.lat)::geography END,
cafes.id ASC
OFFSET offset_value FETCH FIRST limit_value ROWS ONLY;
END;
$$ LANGUAGE plpgsql;This was the first iteration of my search engine.
- Returns the number of cafes based on search filters
- Returns the results based on search filters
- Sortable. Sorts by distance by default.
I ran the query and call it on the homepage and it works as intended!
const supabase = createServerClient()
const sanitisedQuery = props?.query
? decodeURIComponent(props?.query || "")
: undefined
const sanitisedSort = props?.sort
? decodeURIComponent(props?.sort || "")
: undefined
const { data: cafes, error } = await supabase.rpc(
"search_cafes_experimental_2",
{
search_input: sanitisedQuery,
lat: props?.userLocation.lat,
long: props?.userLocation.lng,
filter_locales: props?.filters?.locales?.split(","),
filter_categories: props?.filters?.categories?.split(","),
filter_atmospheres: props?.filters?.atmospheres?.split(","),
filter_accessibilities: props?.filters?.accessibilities?.split(","),
filter_amenities: props?.filters?.amenities?.split(","),
filter_offerings: props?.filters?.offerings?.split(","),
filter_service_options: props?.filters?.serviceOptions?.split(","),
filter_payment_methods: props?.filters?.paymentMethods?.split(","),
sort_by_created_at: sanitisedSort?.split("-")[0] === "created_at",
sort_by_rating: sanitisedSort?.split("-")[0] === "rating",
sort_by_name: sanitisedSort?.split("-")[0] === "name",
sort_order:
sanitisedSort?.split("-")[1]?.split(":")[1] === "true" ? "asc" : "desc",
sort_by_nearby: props?.nearby,
limit_value: 12,
offset_value: (Number(props?.page || 1) - 1) * 12
}
)
if (error?.message) {
console.error(error.message)
}
return { cafes, count: cafes?.[0]?.result_count || 0 }The number of lines of code has also reduced to 87. Awesome, so I guess that's it then!
Performance tuning
Few days later, I realised that this function is very very VERY slow.
I checked the logs for the slowest response time and get the highest origin_time
and it was about 50 seconds!
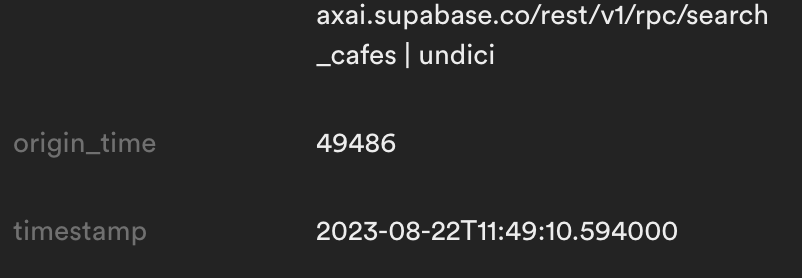
Here are the load times on the browser when I first load the home page:

18 seconds to FCP?! I started looking into performance tuning, in hopes that I will be able to identify the factors that are affecting the performance of this function.
I found out about pgMustard and it was really easy to use, but trying to analyze a function query really did not produce any potential areas to improve on.
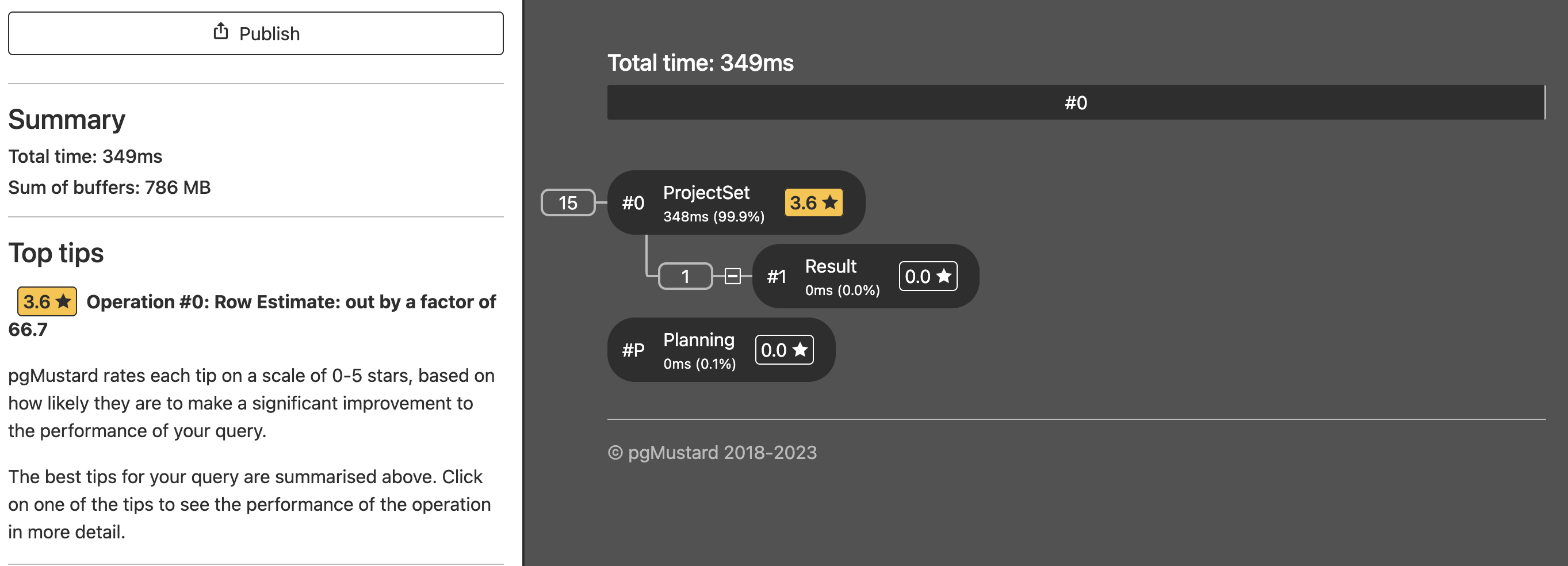
pgMustard is a tool I will definitely revisit again in the future. Check out their youtube channel. The founder explains how to use it and how it can resolve some query problems.
Then, I prompted ChatGPT
if i were to give you a postgres query, can you help modify it to make it more optmised?I copy and pasted my function query and ChatGPT responded a list of possible ways to optimise performance
-
Indexing: Ensure that the columns used in join conditions, filtering, and sorting are properly indexed. Indexing can significantly speed up data retrieval. Based on your queries, it seems like the id columns in various tables, as well as fts and location columns, should be indexed.
-
Reduce Subqueries: In your function, you have several subqueries that aggregate data from related tables. Instead of using subqueries in the main query, you can consider creating views for these aggregated data and join the views in the main query. This can help simplify the main query and improve its readability.
-
Caching: If the data in your related tables (e.g., cafe_amenities, cafe_atmospheres) doesn't change frequently, you could consider creating materialized views for these aggregations. Materialized views store the aggregated results and can be refreshed periodically or when new data is added. This can help reduce the complexity of your query and improve performance.
-
Use of EXISTS: In some cases, you can use the EXISTS keyword to check for the existence of related data rather than joining with a subquery that retrieves the data. This can lead to more efficient query plans.
-
Review Data Types: Make sure the data types used for comparisons and joins are consistent. Mismatched data types can lead to slower query execution.
-
Batch Loading: If you're dealing with a large amount of data, consider using pagination and fetching data in batches rather than loading all the data at once. This can help manage memory and improve query performance.
-
Profiling and Testing: Always profile and test your queries with real data and production-like scenarios to identify bottlenecks and optimize accordingly. PostgreSQL provides tools like EXPLAIN to analyze query execution plans.
-
Regular Maintenance: Ensure that your database is regularly maintained, including vacuuming and analyzing to optimize performance.
Here are the ones that I managed to do and worked:
- Reduce subqueries by using CTEs
- Create materialized views for aggregated data
- Using EXISTS in my WHERE conditions
Here are what didn't work:
- Tune
work_mem
Honestly, with the level of knowledge I have about SQL right now, I do not dare touching work_mem params...
Benchmarking
I will be benchmarking the results of the optimisations based on the execution_time
that I get from running
explain (analyze, format text, buffers, verbose, settings)
select search_cafes_experimental_2('cafe', 3.139003, 101.686852, array ['Assistive hearing loop'], array ['Wi-Fi'], array ['Cozy'], array ['Cafe'], array ['Coffee'], array ['Credit cards'], array ['Dine-in'], array ['Kuala Lumpur'])This call returns the simplest result. This is so that I can benchmark the performance at it's less intensive state.
Starting line
To see the initial query, go here.
Reducing subqueries and create materialized views
First thing I started doing was to move all subqueries into CTEs and then created materialized views for all the subqueries that aggregates.
CREATE MATERIALIZED VIEW cafe_address_locale_names_agg AS
SELECT cafe_id, array_agg(locale) AS locale_names
FROM cafe_addresses
GROUP BY cafe_id;
CREATE MATERIALIZED VIEW cafe_amenity_names_agg AS
SELECT cafe_id, array_agg(amenity_name) AS amenity_names
FROM cafe_amenities
GROUP BY cafe_id;
-- Other materialized views create queries
CREATE INDEX idx_cafe_address_locale_names_agg_cafe_id ON cafe_address_locale_names_agg (cafe_id);
CREATE INDEX idx_cafe_amenity_names_agg_cafe_id ON cafe_amenity_names_agg (cafe_id);
-- Other index creation for the materialized viewsThen I implemented those views into the function within the JOINs and WHEREs
-- Function code...
BEGIN
WITH filtered_images AS (
SELECT cafe_id, images_cafes.base64, images_cafes.url
FROM images_cafes
WHERE images_cafes.url IS NOT NULL OR images_cafes.base64 IS NOT NULL
),
cafes_data AS (
SELECT
cafes.id,
cafes.name,
cafes.rating,
cafes.address,
cafes.location,
ST_Distance(cafes.location, ST_Point(search_cafes_experimental_2.long, search_cafes_experimental_2.lat)::geography) AS dist_meters
FROM cafes
LEFT JOIN filtered_images ON cafes.id = filtered_images.cafe_id
LEFT JOIN cafe_address_locale_names_agg ON cafes.id = cafe_address_locale_names_agg.cafe_id
-- Other left joins
WHERE
(search_input IS NULL OR cafes.fts @@ plainto_tsquery('english', search_input))
AND (filter_locales IS NULL OR cafe_address_locale_names_agg.locale_names && filter_locales)
AND (filter_amenities IS NULL OR cafe_amenity_names_agg.amenity_names && filter_amenities)
-- Other filter conditions
)
SELECT COUNT(*) INTO result_count
FROM cafes_data;
RETURN QUERY
WITH filtered_images AS (
SELECT cafe_id, images_cafes.base64, images_cafes.url
FROM images_cafes
WHERE images_cafes.url IS NOT NULL OR images_cafes.base64 IS NOT NULL
),
cafes_data AS (
-- Similar to CTE above
)
SELECT
result_count,
cafes_data.id,
cafes_data.name,
cafes_data.rating,
cafes_data.address,
base64,
url,
ST_AsText(cafes_data.location) AS location,
cafes_data.dist_meters
FROM cafes_data
-- Sorts and offsets
END;
$$ LANGUAGE plpgsql;Once I was done with that, I ran the query and the execution time went down by 70%!
I was surprised how effective Materialized View is. It helps to cache the aggregate queries which helps in my situation since the values don't change much as the aggregated column values are mostly constant.
On to the next one!
Using EXISTS
EXISTS helps in checking if the requested values exists within the aggregated values first before returning the values. To put it layman terms,
I see a door infront of me and I want to know if there is a pot of gold inside.
- Without EXISTS - I walk into the door and I would either walk out with a pot of gold, or empty handed.
- With EXISTS - I walk to the door and peek through the keyhole to see if there is a pot of gold or not, eliminating the 50% chance of feeling upset about not getting a pot of gold.
At least that is how I understand it.
I started implementing EXISTS on my WHERE conditions
WHERE
(search_input IS NULL OR cafes.fts @@ plainto_tsquery('english', search_input))
AND (filter_locales IS NULL OR EXISTS (
SELECT 1
FROM cafe_address_locale_names_agg
WHERE cafes.id = cafe_address_locale_names_agg.cafe_id AND cafe_address_locale_names_agg.locale_names && filter_locales
))
AND (filter_amenities IS NULL OR EXISTS (
SELECT 1
FROM cafe_amenity_names_agg
WHERE cafes.id = cafe_amenity_names_agg.cafe_id AND cafe_amenity_names_agg.amenity_names && filter_amenities
))
-- Applied the same logic to the other conditionsThen I ran the query again, and boom! Another 50% decrease in response time! Bringing the total execution time down to 45ms!
That is 85% decrease in total from the initial execution time.
Performance on the Web
After further touchups on the search engine query and some quality of life improvements on Cafeist, I deployed it to production and started to test out the performance by benchmarking the before and after load times and it really shows
Before the optimisation, the load times were between 6 seconds to 16 seconds. I tested this out by clicking random filters until the URL became unreadable on the searchbar.
After the optimisation, load times were down between 500 ms to 3 seconds max. That is a very big improvement.

The calls were made 4 times after selecting multiple filters.
Further development
Knowing how deep the rabbit hole goes for SQL, I know that there can be more improvements but for now, I am good with what I have achieved. Getting an 85% reduction in execution time is mind-boggling even for me.
There are platforms like Algolia that can just solve this problem with a click of a button, and it did cross my mind before but if I am being honest, the issue that I ended up solving, wasn't really a big deal and I am not dealing with millions of data. Perhaps when my data scales in the future, I will start branching out to using different tools since time would be the main factor in cost.
That said, I pretty much learn alot about SQL queries in 3 days. Would I do it again? Maybe. Do I like it? Definitely no.
